")
大数据时代,企业和个人都想通过数据分析来获取信息、了解行业和竞对、解决业务问题。那数据从何而来?正如我们平时有问题找“度娘”一样,数据的一个重要来源就是互联网,爬虫就是获取互联网数据的手段,前端时间本数据分析狮,兼职了两周的爬虫工程师,今天跟大家白话白话爬虫那些事儿。
白话爬虫
爬虫官方定义:网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常被称为网页追逐者),是一种按照一定的规则,自动地抓取万维信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
白话爬虫:利用程序模拟人的上网行为进行网络索引,获取网页中特定的信息,实现短时间、不间断、实时获取网络数据。
个人浏览器上网原理图
爬虫程序可以简单想象为替代浏览器的功能【发送url请求,解析服务器返回的HTML文档】并将获取的数据存储到数据库或文件中,同时针对网站的反爬策略,需要对自己进行伪装,也就是跟浏览器发送的信息一样携带上我是谁?(cookie信息)、我从哪里来(IP地址,使用代理IP)、我的浏览器型号(User-Agent)、使用的方法(get、post等)、访问的信息。
爬虫原理图
python爬虫代码案例
需求:爬取某一关键字(用户自定义)的百度前几页(用户自定义)的搜索结果的网站地址和主题
代码:
class crawler: &39;&39;&39; url = &39; urls = [] o_urls = [] html = &39; total_pages = 5 current_page = 0 next_page_url = &39; timeout = 60 headersParameters = { &39;: &39;, &39;: &39;, &39;: &39;, &39;: &39;, &39;: &39; } def __init__(self, keyword): self.keyword = keyword self.url = &39;+quote(keyword)+&39; self.url_df = pd.DataFrame(columns=[&34;]) self.url_title_df = pd.DataFrame(columns=[&34;,&34;]) def set_timeout(self, time): &39;&39;&39; try: self.timeout = int(time) except: pass def set_total_pages(self, num): &39;&39;&39; try: self.total_pages = int(num) except: pass def set_current_url(self, url): &39;&39;&39; self.url = url def switch_url(self): &39;&39;&39; if self.next_page_url == &39;: sys.exit() else: self.set_current_url(self.next_page_url) def is_finish(self): &39;&39;&39; if self.current_page >= self.total_pages: return True else: return False def get_html(self): &39;&39;&39; r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters) if r.status_code==200: self.html = r.text 34;-----------------------------------------------------------------------& print(&34;,self.url) print(&34;,self.html) 34;-----------------------------------------------------------------------&39;&39;[ERROR]&39;get此url返回的http状态码不是200&39;&39;从当前html中解析出搜索结果的url,保存到o_urls&39;&39;href\=\&34; class\=\&34;&39;href\=\&34; class\=\&34;.* data-tools=\&34;title&34;url&39;,self.html) 去重 去重 self.titles = titles self.o_urls = o_urls 39; href\=\&34; class\=\&34;&39;https://www.baidu.com&39;&39;&39;获取重定向url指向的网址&39;&禁止自动跳转 if r.status_code == 302: try: return r.headers[&39;] 返回源地址 def transformation(self): &39;&39;&39; self.urls = [] for o_url in self.o_urls: self.urls.append(self.get_real(o_url)) def print_urls(self): &39;&39;&39; for url in self.urls: print(url) for title in self.titles: print(title[0]) def stock_data(self): url_df = pd.DataFrame(self.urls,columns=[&34;]) o_url_df = pd.DataFrame([self.o_urls,self.urls],index=[&34;,&34;]).T title_df = pd.DataFrame(self.titles,columns=[&34;,&34;]) url_title_df = pd.merge(o_url_df,title_df,left_on=&34;,right_on=&34;,how=&34;) url_titles_df = url_title_df[[&34;,&34;]] self.url_df = self.url_df.append(url_df,ignore_index=True) self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True) self.url_title_df[&34;] = len(self.url_title_df)* [self.keyword] def print_o_urls(self): &39;&39;&39; for url in self.o_urls: print(url) def run(self): while(not self.is_finish()): self.get_html() self.get_urls() self.transformation() c.print_urls() self.stock_data() time.sleep(10) self.switch_url()API接口
爬取百度关键词 timeout = 60 totalpages=2 前两页 baidu_url = pd.DataFrame(columns=[&34;,&34;,&34;]) keyword=&34; c = crawler(keyword) if timeout != None: c.set_timeout(timeout) if totalpages != None: c.set_total_pages(totalpages) c.run() # print(c.url_title_df) baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)获取关键词“数据分析”的百度搜索结果的前两页信息
66财经推荐您看:
vendors和suppliers的区别(supplier with)
(责任编辑:66财经)
版权声明:本文内容由互联网用户自发贡献,已注明文章出处,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如果发现本站有涉嫌抄袭侵权/违法违规的内容,欢迎发送邮件至【68407578@qq.com】举报,并提供相关证据及涉嫌侵权链接,一经查实,本站将立刻删除涉嫌侵权内容。
本文标题:【网络爬虫的意思(网络爬虫实战)】
本文链接:https://www.nxgjcc.com/9732.html
- 2023-10-21 如何信用贷100万方法(普通人怎样能贷100万)
- 2024-03-28 缩量上涨是好事吗(缩量上涨的股票好不好)
- 2023-09-13 2016 营改增 对建筑企业影响(浅谈营改增对建筑施工企业的影响)
- 2024-02-16 天泰华府售楼处电话(天泰华府附近饭店)
- 2024-04-01 周立波与神秘富豪(周立波与男富豪)
- 2023-10-17 中国银行无抵押信用贷款额度(中国银行信用贷款要求)
- 2023-12-11 美国股市开盘时间和收盘时间(国际股市开盘时间和收盘时间)
- 2023-10-13 邮政无密码存单家人能取么(邮政存单无密码可以由他人代取吗)
- 2023-11-28 航空公司兑换里程积分怎么用(兑换航空里程的信用卡)
- 2024-02-20 怎么看信用卡的级别(怎么看信用卡等级)
- 搜索
-
- 相关推荐


为什么b股股价越来越低(b股为什么叫b股)
2024-05-10-
什么是洗钱?洗钱有哪些危害(什么是洗钱罪?如何认定?)
2024-04-30 
通货膨胀有多可怕?(解读通货膨胀)
2024-04-17
盘亏库存现金所涉及的会计科目是(库存现金盘亏的分录怎么写?)
2024-04-15
什么是独角兽企业和四新类企业(2023独角兽企业榜单)
2024-04-11-
财政部规范推进ppp(财政部ppp项目指南)
2024-04-10 -
欧元涨跌(欧元又涨了)
2024-03-31 
营口港详细情况(营口港属于哪个城市)
2024-03-30-
西部证券最近有什么利好出台(西部证券股票行情分析)
2024-03-28 
办公用品发票可以不开明细吗(办公用品发票单位是什么)
2024-03-27
交银集团(交通银行谁题)
2024-05-16
交通银行买单吧商城没有了吗(交通银行的买单吧在哪里)
2024-05-16-
交通银行信用卡kpl(2021年交通银行信用卡活动)
2024-05-16 
不用的信用卡被扣年费(信用卡扣)
2024-05-16
做人工客服(智能客服怎么转人工)
2024-05-16
怎么秒办信用卡(快速申请信用卡)
2024-05-16
积分换点话费(积分换电费怎么换)
2024-05-16
办信用卡注意(办信用卡有什么注意事项吗?)
2024-05-16
上海市居住证积分续签时间(上海市居住证积分续签条件)
2024-05-16
机场办信用卡有什么坑(机场办信用卡是诈骗吗)
2024-05-16-
支付宝可以给微信好友转账吗(支付宝可以给微信转账么)
2024-01-04 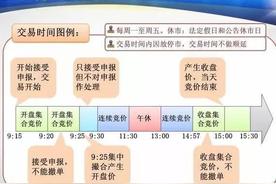
集合竞价通俗易懂(集合竞价?)
2023-12-04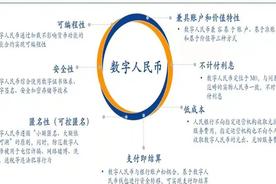
什么是数字货币,央行为什么要发行数字货币(什么是数字货币合约交易)
2023-10-10
2020年广发信用卡(广发银行发展历史)
2024-04-15
商业电子承兑到期怎么进账(商业电子承兑汇票到期后多少天能兑现)
2024-03-08
普惠金融服务窗口(线上业务 普惠金融)
2024-04-09
如何买火车票更便宜(如何买火车票便宜)
2024-01-27
香港富豪日常生活(香港富豪知乎)
2023-12-02
理财收益怎么理财(怎么理财收益)
2023-10-17-
信用卡怎么用才能提高额度(信用卡怎么用支付宝提现)
2024-02-22
